

Figma Weave คืออะไร? เครื่องมือ AI ต่อโหนดสร้างวิดีโอ
/ 6 min read
Table of Contents
ทุกวันนี้ AI สร้างภาพสร้างวิดีโอได้เก่งขึ้นมากๆ แต่ส่วนใหญ่ยังเป็นแบบ “พิมพ์ prompt แล้วลุ้น” ได้มาแล้วถ้าไม่ถูกใจก็พิมพ์ใหม่ ควบคุมรายละเอียดยาก แล้วถ้ามีเครื่องมือที่ให้เรา ต่อขั้นตอน เองได้เหมือนต่อบล็อก แถมเลือกได้ด้วยว่าจะใช้โมเดลตัวไหนล่ะ? นั่นแหละคือ Figma Weave ที่ผมเพิ่งไปลองเล่นมา
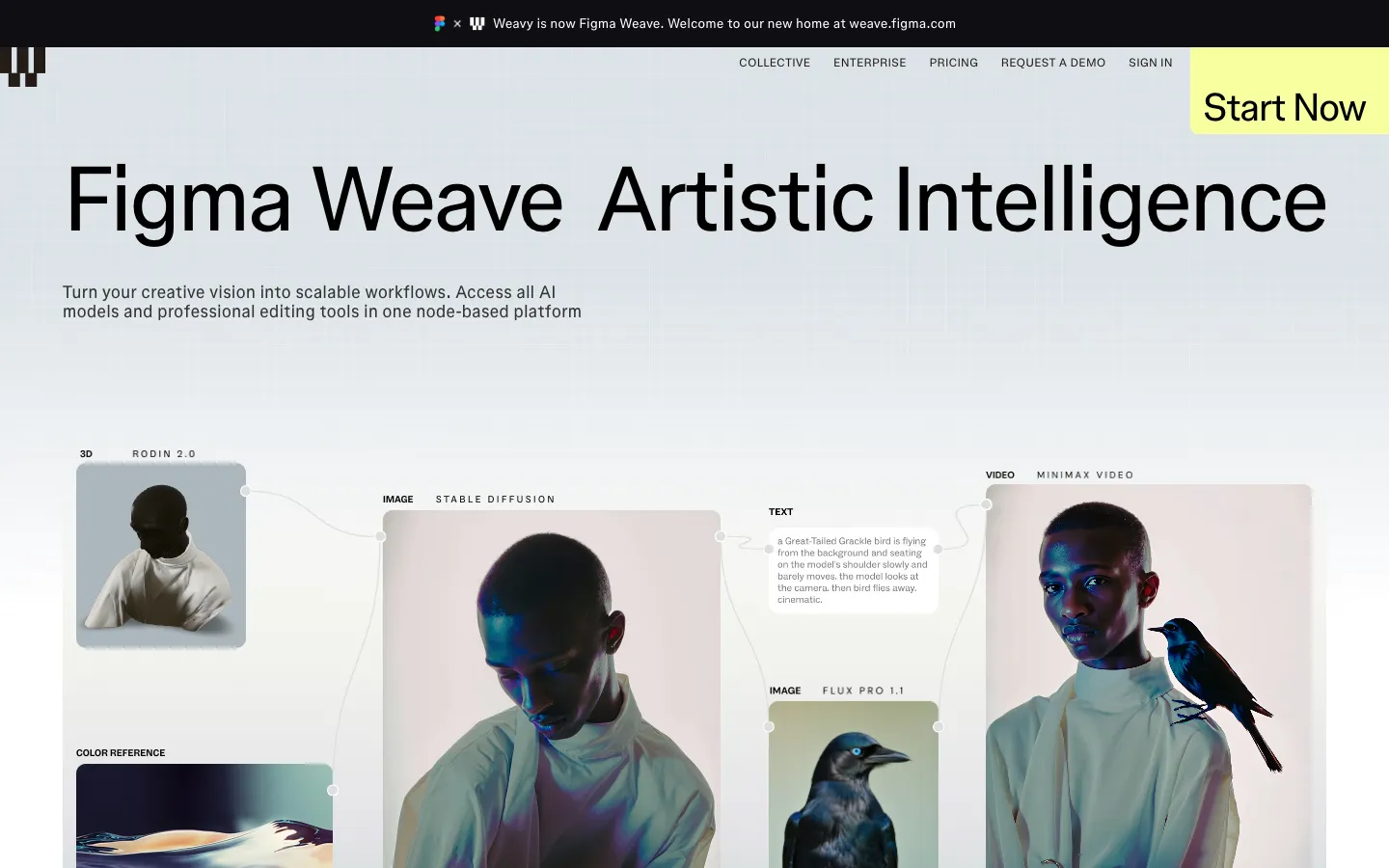
Figma Weave คืออะไร
Weave เดิมชื่อ Weavy เป็นสตาร์ทอัพที่ Figma ซื้อมาแล้ว rebrand ใหม่ (อ่านประกาศจาก Figma) มันคือแพลตฟอร์ม AI สร้างและแก้ media แบบ node-based ครบทั้งภาพ วิดีโอ แอนิเมชัน และ VFX อยู่ในหน้าเว็บเดียว ตอนนี้ยังเป็นตัวแยกอยู่ที่ weave.figma.com และ Figma บอกว่าจะรวมเข้าระบบหลักช่วงปลายปี
เบื้องหลัง: จาก Weavy ที่เทลอาวีฟ
Weave ไม่ได้เกิดในบ้าน Figma แต่เริ่มจากสตาร์ทอัพชื่อ Weavy ที่ก่อตั้งปี 2024 ที่เมืองเทลอาวีฟ ประเทศอิสราเอล โดยทีมผู้ก่อตั้งที่มาจากสาย VFX, แอนิเมชัน และงานโปรดักชันสร้างสรรค์ พออ่านประวัติทีมแล้วก็เข้าใจเลยว่าทำไมเครื่องมือมันถึงคิดมาแบบ “คนทำงานภาพจริง” ไม่ใช่แค่ของเล่น AI พิมพ์ prompt เล่นๆ
ต่อมา Figma ประกาศเข้าซื้อกิจการเมื่อ 30 ตุลาคม 2025 แล้ว rebrand เป็น Figma Weave ตอนนี้ยังเปิดเป็นเว็บแยกที่ weave.figma.com และ Figma บอกว่าจะค่อยๆ ดึงความสามารถด้านภาพ/วิดีโอ/แอนิเมชัน/โมชัน/VFX เข้าไปรวมในอีโคซิสเต็มหลักของตัวเอง
จุดเด่นที่ 1 ทำงานแบบ “ต่อโหนด”
แทนที่จะเป็นช่องพิมพ์ prompt ช่องเดียว Weave ให้เราวางงานเป็น โหนด (node) แล้วลากเส้นเชื่อมกัน เช่น โหนด prompt → โหนดสร้างภาพ → โหนดแปลงเป็นวิดีโอ → export ทั้งหมดอยู่ในแคนวาสเดียว อยากแตกไปลองอีกแบบก็ก็อปโหนดไปแขนงใหม่ได้ ไม่ต้องเริ่มใหม่ทั้งหมด (เดี๋ยวมีรูปแคนวาสจริงให้ดูในหัวข้อ “ผมลองสร้างวิดีโอตัวแรก” ข้างล่าง)
ความรู้สึกตอนใช้คือมันเหมือนต่อท่อน้ำ เห็นภาพชัดว่าอะไรไหลไปไหน แก้ตรงไหนก็เห็นผลเป็นจุดๆ ไม่ใช่กล่องดำที่พิมพ์เข้าไปแล้วได้อะไรไม่รู้ออกมา
จุดเด่นที่ 2 เลือกโมเดลได้เอง เพียบ
อันนี้คือสิ่งที่ผมชอบสุดเลย คือ Weave ไม่ได้ผูกกับโมเดลเดียว แต่ให้เลือกได้ว่าจะใช้ตัวไหนกับงานไหน ฝั่งวิดีโอมีตั้งแต่ Sora 2, Veo 3.1, Kling, Runway Gen-4, Seedance ฯลฯ ส่วนภาพก็มี Flux, Ideogram, Nano-Banana และอื่นๆ อีกยาว
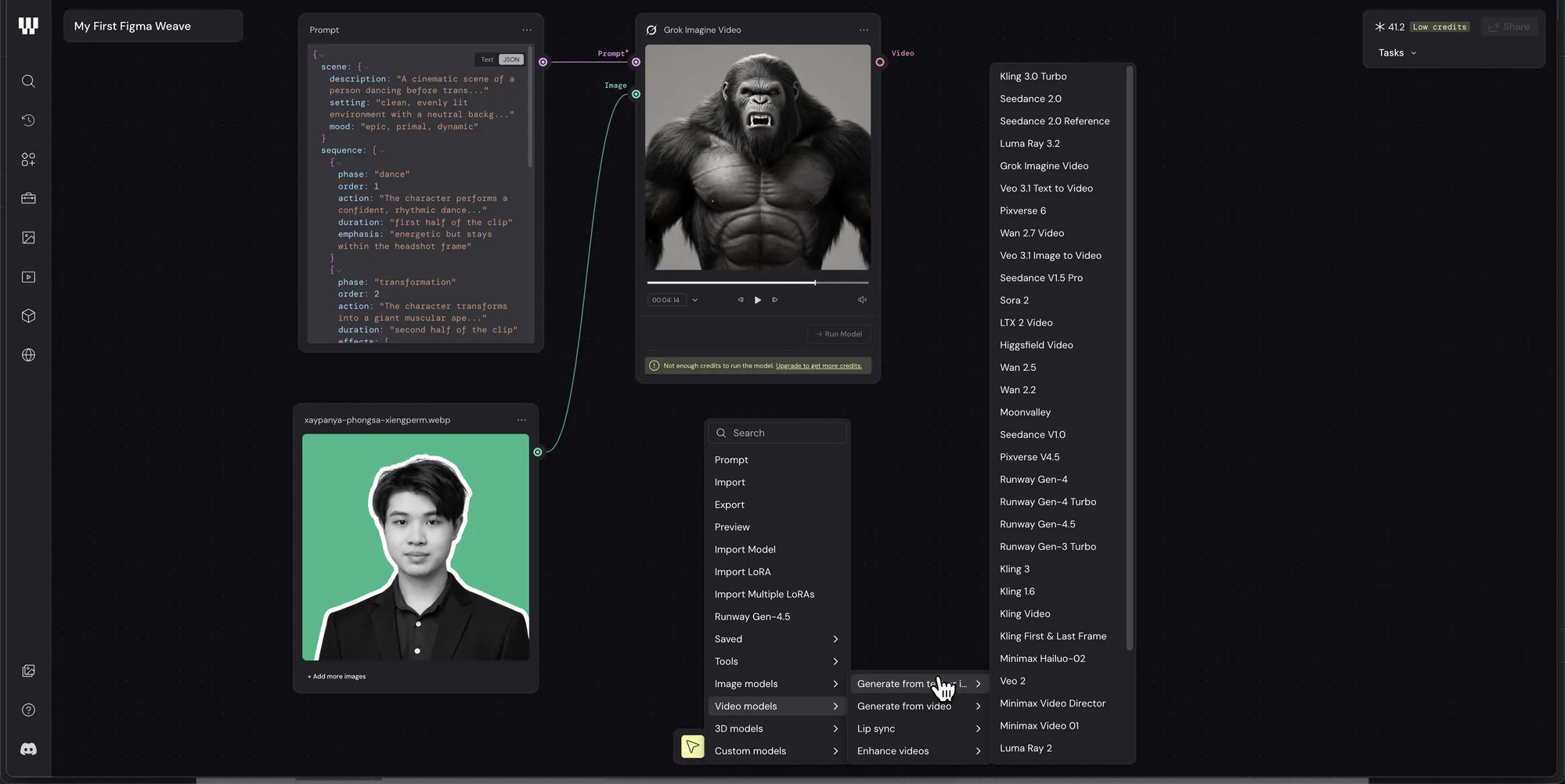
ข้อดีคือแต่ละโมเดลเก่งคนละแบบ บางตัวเก่งภาพเหมือนจริง บางตัวเก่งงานเคลื่อนไหวลื่นๆ การได้สลับลองในที่เดียวโดยไม่ต้องเปิดสิบเว็บ มันสะดวกจริง
แล้วมันสร้างมายังไง
เหตุผลที่ Weave มีโมเดลให้เลือกเยอะขนาดนี้ คือมันไม่ได้ เทรนโมเดล AI เอง แต่ทำตัวเป็น ตัวกลาง (aggregator) ที่ดึงโมเดลจากเจ้าต่างๆ มารวมไว้บน canvas เดียว ทั้งฝั่งวิดีโอ (Seedance, Sora, Veo), ฝั่งภาพ (Flux, Ideogram) และตัวอื่นๆ อย่าง Nano-Banana หรือ Seedream
พูดง่ายๆ คือ Weave ขายความเป็น “โต๊ะทำงาน” ที่จัดวางโมเดลของคนอื่นให้เราต่อกันได้สะดวก ไม่ใช่ขายตัวโมเดลเอง นี่คือเหตุผลที่มันทำงานบน browser ล้วนๆ ได้ (งานเรนเดอร์หนักๆ วิ่งอยู่บน cloud ของโมเดลปลายทาง) และเป็นเหตุผลที่เราจ่ายเป็น เครดิต เพราะทุกครั้งที่กดรัน มันไปเรียกใช้โมเดลปลายทางที่มีต้นทุนจริง
ข้อดีของวิธีนี้คือพอมีโมเดลใหม่ดังๆ ออกมา Weave ก็เสียบเพิ่มเข้าระบบให้เลือกได้เลย เราไม่ต้องไปไล่สมัครทีละสิบเว็บเอง
”อ้าว นี่มัน ComfyUI ดีๆ นี่เอง”
ใครที่เคยเล่นสาย AI gen มาก่อนพอเห็นระบบโหนดน่าจะนึกถึง ComfyUI ทันที เพราะตัวนั้นก็ต่อโหนดสร้างภาพ/วิดีโอเหมือนกัน และเป็นโอเพนซอร์สฟรีด้วย ผมเลยลองคิดว่า Weave มันต่างยังไง
ของมันคนละจุดยืนกันครับ ComfyUI รันบนเครื่องเราเอง (หรือ server ที่เราเช่า) ฟรีก็จริง แต่ต้องมี GPU แรงๆ, ตั้งค่าเอง, โหลด model มาลงเอง และต้องไล่หา node เสริมเองเวลาอยากได้ฟีเจอร์ใหม่ ส่วน Weave จับอีกทาง คือไม่ต้องมีการ์ดจอ ไม่ต้องลงอะไร เปิดเว็บก็ใช้ได้เลย model รวมมาให้พร้อม แลกกับการที่ต้องจ่ายเป็นเครดิต
พูดง่ายๆ คือ ComfyUI เหมาะกับคนที่อยากคุมทุกอย่างเองและมีเครื่องแรงพอ ส่วน Weave เหมาะกับคนที่ขี้เกียจตั้งของ อยากเปิดมาแล้วทำงานได้เลย ยอมจ่ายเพื่อความสะดวก เลือกตามจริตและงบได้เลย
ผมลองสร้างวิดีโอตัวแรก
ผมเอารูปตัวเอง (รูปธรรมดาที่เอามาแก้ใส่พื้นเขียวเอง) โยนเข้าไปเป็นโหนดรูป แล้วเขียน prompt เป็น JSON สั่งบทคร่าวๆ ประมาณนี้
{ "scene": "ช็อตสไตล์หนังสารคดี ชายหนุ่มยืนอยู่กลางสตูดิโอโล่งๆ", "sequence": [ { "phase": "dance", "action": "เต้นจังหวะมั่นใจ กล้องระยะใกล้" }, { "phase": "transform", "action": "ค่อยๆ แปลงร่างเป็นลิงยักษ์กล้ามโต" } ]}เขียนบทเป็น JSON แบบนี้ดีตรงที่บอกโมเดลได้ละเอียดว่าช็อตไหนทำอะไร ไม่ใช่โยนประโยคเดียวให้มันเดาเอง จากนั้นต่อสายเข้าโหนด Grok Imagine Video แล้วกดเรนเดอร์
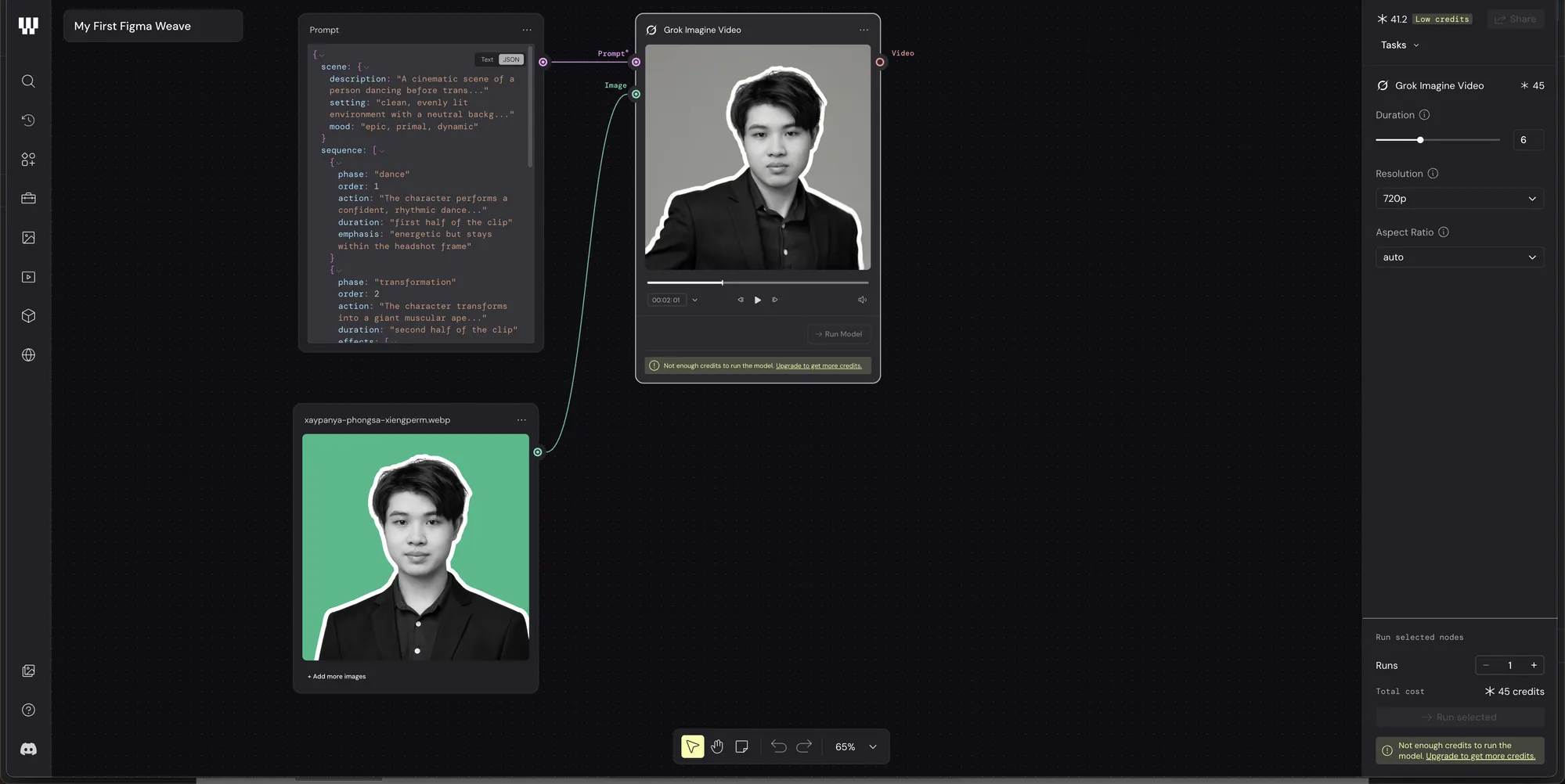
ผมลองอยู่หลายแบบ ตัวที่เอามาให้ดูนี้เป็นอีก experiment นึงที่ลองแปลงร่างสไตล์อุลตร้าแมน เริ่มจากรูปนิ่งแล้วค่อยๆ ขยับ แล้วแปลงร่างเป็นวิดีโอ

จากรูปตัวเองธรรมดา กลายเป็นวิดีโอแปลงร่างได้ในไม่กี่คลิก
มีเรื่องต้องบอกตามตรงคือมันใช้ เครดิต ในการเรนเดอร์ ของผมเล่นไปเล่นมาเครดิตหมดเร็วมาก (ขึ้น “Low credits” แล้วรันต่อไม่ได้จนกว่าจะเติม) ฉะนั้นใครจะลองจริงจังก็เตรียมงบไว้หน่อย ไม่ใช่ฟรีไม่อั้น
ตัวอย่าง workflow ที่ซับซ้อนขึ้น
ของผมข้างบนคือแบบง่ายสุด แต่พลังจริงๆ ของระบบโหนดจะเห็นตอนต่อกันเป็นสายการผลิต ผมไปเจอ workflow ตัวอย่างชื่อ “Don’t post your work, post you working” ที่ต่อกันหลายขั้น เริ่มจากโหนด Prompt + รูป reference ของคน ส่งเข้าโหนด Any LLM ให้ช่วยขยายเป็นบทวิดีโอละเอียด แล้วส่งต่อให้ Seedance 2.0 สร้างวิดีโอ จากนั้นเข้าโหนด Compositor เพื่อแปะข้อความทับ (“DON’T POST YOUR WORK”) ก่อนออกที่โหนด Output
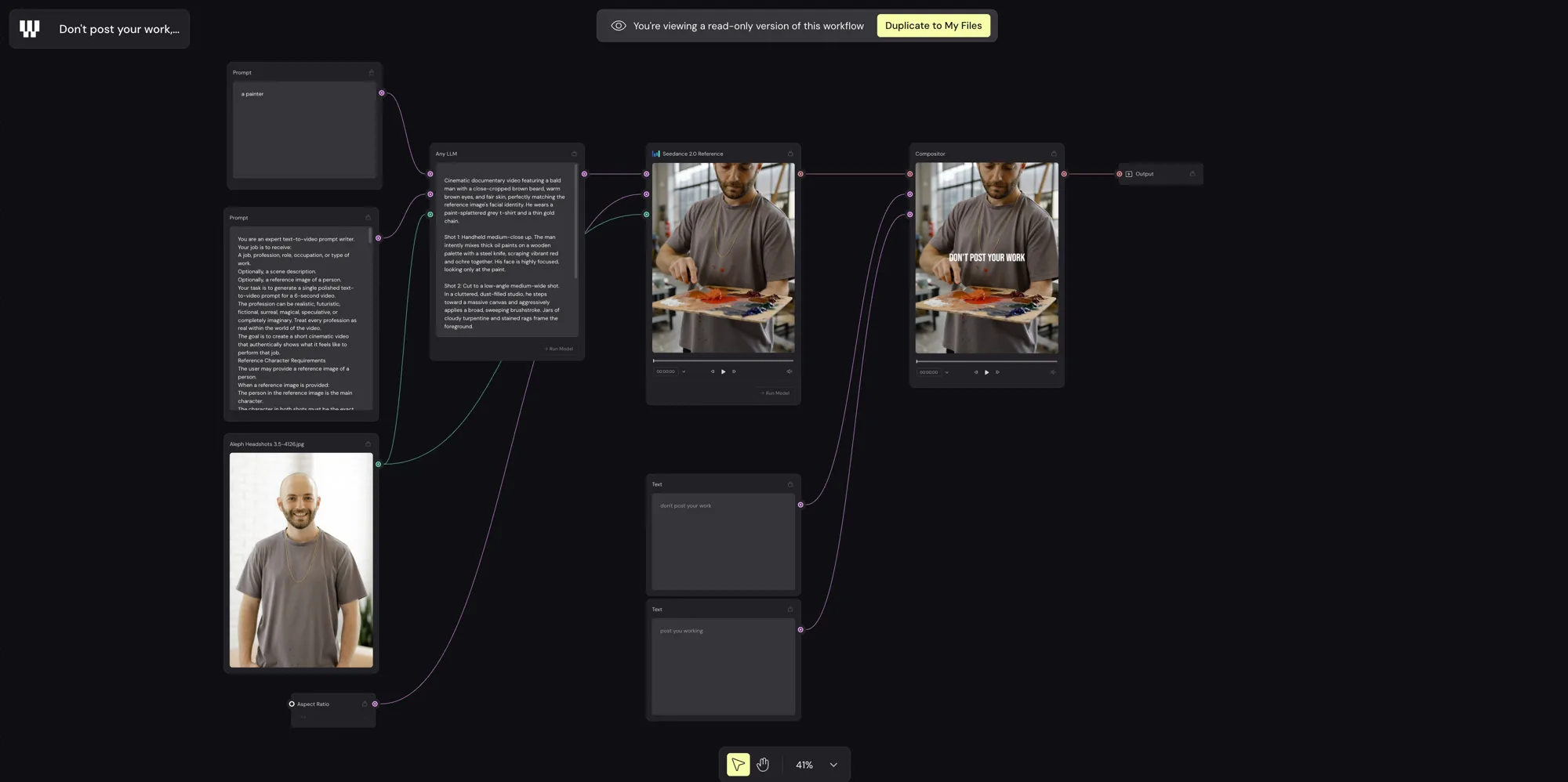
จุดที่ผมว่าฉลาดคือมี โหนด LLM คั่นกลาง เราพิมพ์ prompt สั้นๆ แค่ “a painter” มันก็ไปขยายเป็นบทแบบ shot-by-shot ให้ (“Shot 1: ภาพมือถือระยะใกล้ ชายคนหนึ่งกำลังผสมสีน้ำมัน…”) แล้วค่อยป้อนเข้าโมเดลสร้างวิดีโอ นี่แหละพลังของระบบโหนด คือเอาความสามารถ AI หลายตัว (เขียนบท + สร้างภาพ + ใส่ข้อความ) มาต่อกันเป็นไปป์ไลน์เดียวจบ
ผลลัพธ์ที่ออกมาก็ประมาณนี้

ข้อจำกัดที่เจอจริงตอนใช้
จะให้เชียร์อย่างเดียวก็ไม่แฟร์ ลองมาแล้วเจออะไรบ้างเล่าให้ฟัง
- เครดิตหมดไวมาก อันนี้สะดุดสุด กดเล่นไม่กี่ทีก็ขึ้น “Low credits” แล้ว ยิ่งโมเดลวิดีโอตัวเทพๆ ยิ่งกินเครดิตหนัก ใครจะใช้จริงจังต้องวางแผนงบ
- ผลลัพธ์ยังลุ้นอยู่ดี ถึงจะคุมเป็นขั้นได้ แต่ตัวโมเดลก็ยังเป็น AI วิดีโอ บางทีก็ได้นิ้วเกิน หน้าเพี้ยน หรือการเคลื่อนไหวแปลกๆ ต้องเรนใหม่อยู่หลายรอบ (ซึ่งก็กินเครดิตอีก)
- มีบันไดให้ปีนนิดหน่อย ระบบโหนดไม่ได้ยาก แต่ก็ไม่ได้เปิดมาเข้าใจทันทีเหมือนช่องพิมพ์ prompt เดียว ต้องลองเล่นสักพักกว่าจะจับทางว่าโหนดไหนต่อกับโหนดไหน
- ยังเป็นตัวแยก ตอนนี้ยังไม่รวมกับ Figma หลัก ต้องเข้าผ่าน
weave.figma.comต่างหาก ของแบบนี้ระหว่างทางอาจมีเปลี่ยนได้อีก
ไม่ใช่ deal-breaker นะ แค่อยากให้รู้ก่อนว่ามันไม่ใช่ของวิเศษกดทีเดียวได้งานเทพ
อยากลองเอง เริ่มยังไง
ถ้าอ่านมาถึงตรงนี้แล้วคันไม้คันมืออยากลอง ขั้นตอนคร่าวๆ มีแค่นี้
- เข้า weave.figma.com แล้ว login ด้วยบัญชี Figma (ใช้ของเดิมได้เลย ไม่ต้องสมัครใหม่)
- กด Create New File เปิดแคนวาสเปล่า หรือจะหยิบจาก Workflow library ที่เขาทำตัวอย่างไว้ให้มาดัดแปลงก็ได้ ไวกว่าเริ่มศูนย์เยอะ
- ลากโหนด Prompt มาพิมพ์สิ่งที่อยากได้ แล้วต่อเข้าโหนดโมเดล (ภาพหรือวิดีโอ) เลือกรุ่นที่ชอบ
- กด Run รอเรนเดอร์ ถ้าผลออกมายังไม่โดน ก็ปรับ prompt หรือสลับโมเดลแล้วรันใหม่ที่โหนดเดิมได้เลย
เคล็ดลับจากที่ลองมา: เริ่มจากแกะ workflow ตัวอย่างของเขามาดูก่อนว่าเขาต่อโหนดกันยังไง เข้าใจไวกว่านั่งเดาเอง แล้วค่อยลองรื้อสร้างของตัวเอง
เหมาะกับใคร
Figma ยกตัวอย่างคนที่ใช้ Weave ไว้หลายสาย สถาปนิกใช้ทำภาพ staging, ทีม VFX ทำสื่อให้เกม/หนัง/ทีวี, นักการตลาดทำคอนเทนต์โซเชียลกับแบนเนอร์ และดีไซเนอร์ทำ mockup สินค้ากับงานแบรนด์ดิ้ง
สรุปคือถ้าคุณเป็นสายครีเอทีฟ ทำคอนเทนต์ โมชัน หรือทำงานภาพ-วิดีโอที่ต้องลองหลายเวอร์ชัน Weave น่าจะถูกใจ เพราะมันรวมเครื่องมือ AI หลายตัวไว้ในที่เดียวและให้ควบคุมเป็นขั้นเป็นตอน แต่ถ้าแค่อยากได้ภาพเดียวเร็วๆ เครื่องมือ prompt ธรรมดาก็อาจจะพอแล้ว ไม่ต้องมาเรียนรู้ระบบโหนด
ส่วนตัวพอได้ลองแล้วรู้สึกว่ามันคือทิศทางที่น่าสนใจของ AI media แทนที่จะ “สั่งแล้วลุ้น” มันให้เรา ออกแบบกระบวนการ ได้จริง เหมือนเปลี่ยนจากตู้กดสุ่มเป็นโต๊ะทำงานที่เราคุมเองทุกขั้น ใครอยากลองเข้าไปดูได้ที่ weave.figma.com คับ (เตรียมใจเรื่องเครดิตไว้นิดนึง)


