

loops!: คลังสูตรสำเร็จให้ AI วนทำงานเองจนจบ
/ 7 min read
Table of Contents
ถ้าคุณเคยใช้ AI coding agent อย่าง Claude Code หรือ Cursor น่าจะเคยเจอจังหวะนี้ สั่งให้มันแก้บั๊ก มันแก้เสร็จ บอกว่า “เรียบร้อยครับ” แต่พอรันเทสต์จริงดันแดงเถือก เราก็ต้องพิมพ์ใหม่ว่า “เทสต์ยังไม่ผ่านนะ แก้อีกที” วนแบบนี้ไปเรื่อยๆ จนเมื่อยมือ
แล้วถ้าเราไม่ต้องคอยพิมพ์ซ้ำเองล่ะ? ถ้าปล่อยให้ AI มัน รันเทสต์ → เห็นว่าแดง → แก้ → รันใหม่ วนเองจนเขียวค่อยมาบอกเรา?
นั่นแหละคือไอเดียของ loops! เว็บที่ผมเพิ่งไปเจอมา สโลแกนของมันตรงประเด็นมาก “Stop prompting. Start looping.” หยุดพิมพ์สั่งทีละที แล้วมาวนลูปแทน
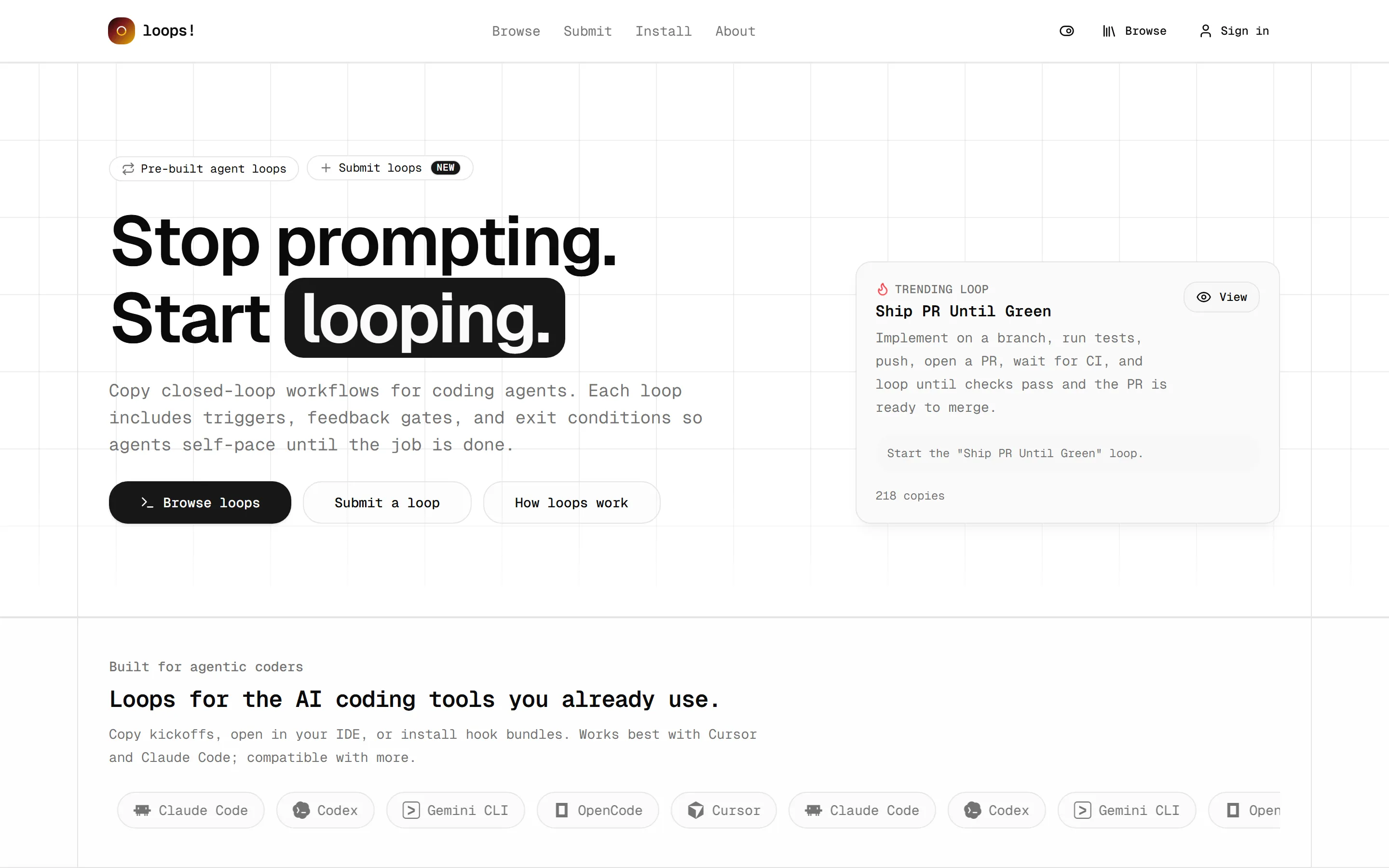
“agent loop” คืออะไร อธิบายแบบบ้านๆ
ปกติเวลาเราใช้ AI agent มันคือการคุยกันแบบ “ถาม-ตอบ” ทีละรอบ เราสั่ง มันทำ จบ ถ้าผลยังไม่ดีเราต้องสั่งต่อเอง การสั่งทีละทีแบบนี้เรียกว่า one-off prompting
agent loop คือการห่อคำสั่งนั้นให้เป็น “วงจรปิด” (closed loop) ที่มันรู้จักวนทำเองได้ โดยในหนึ่งลูปจะมีสามองค์ประกอบหลัก:
- Trigger จุดเริ่ม เช่น “เริ่มทำงานนี้เลย” หรือ “ทุก 15 นาทีให้เช็กที”
- Feedback gate ด่านตรวจระหว่างทาง เช่น คำสั่งรันเทสต์ หรือรัน build ที่ใช้วัดว่า “เสร็จหรือยัง”
- Exit condition เงื่อนไขหยุด เช่น “เทสต์เขียวหมด” หรือ “coverage ถึง 80%”
พอครบสามอย่างนี้ agent ก็จะ act → รัน check → อ่านผล → ทำซ้ำ ไปเองจนกว่าจะเข้าเงื่อนไขหยุด หรือชนเพดานจำนวนรอบที่กำหนด เราแค่นั่งดู
ที่จริงไอเดีย “ปล่อยให้โค้ดวนรันเองแล้วแก้ไป” ไม่ใช่เรื่องใหม่ Simon Willison เคยเขียนไว้ ว่า “This run-the-code-in-a-loop pattern is so powerful that I chose my core LLM tools for coding based primarily on whether they can safely run and iterate on my code.” แปลว่าเขาเลือกเครื่องมือ AI หลักจากความสามารถข้อนี้เลย loops! แค่เอาแพตเทิร์นนี้มาทำเป็นสูตรสำเร็จให้ก๊อปไปใช้

ภาพตัวเองตอนปล่อยให้ agent วนแก้เทสต์ ส่วนเราออกไปกินกาแฟ
หน้าตาของคลัง loop
ในหน้า Browse มี loop ให้เลือกหลายสิบตัว แยกหมวดชัดเจน CI, Testing, Review, Planning ฯลฯ กรองตาม agent ที่ใช้ได้ด้วย (Cursor, Claude Code, Codex, Gemini CLI, OpenCode) แต่ละการ์ดบอกครบว่า loop นี้ทำอะไร มีคน “ก๊อปไปใช้” กี่ครั้งแล้ว ซึ่งเป็นตัวชี้ความนิยมแบบกลายๆ
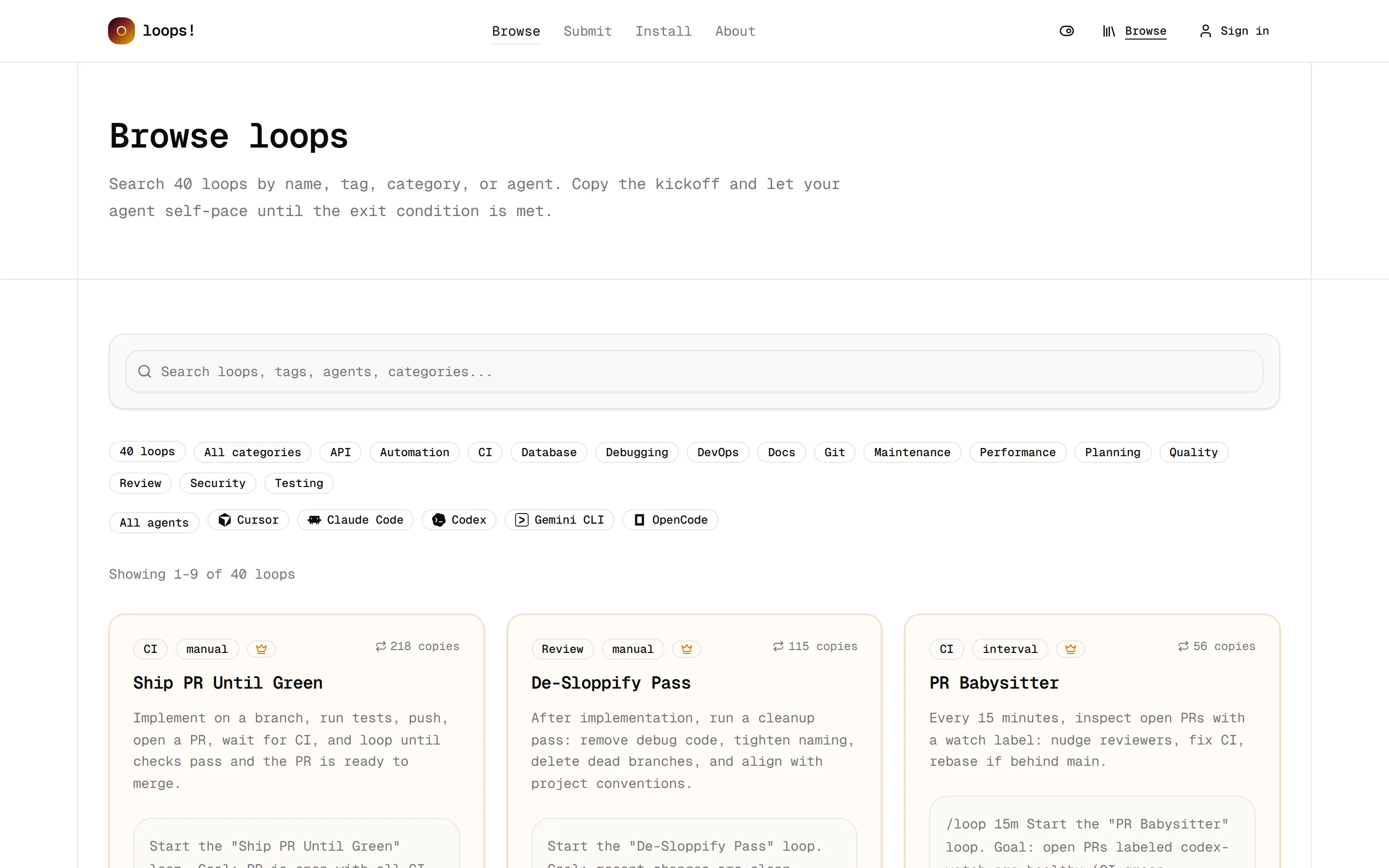
ตัวที่ฮิตสุดตอนที่ผมเข้าไปดูคือ Ship PR Until Green (ก๊อปไปแล้วสองร้อยกว่าครั้ง) งานของมันคือ “implement บน branch, รันเทสต์, push, เปิด PR, รอ CI แล้ววนจนกว่าทุก check จะผ่าน” พูดง่ายๆ คือสั่งทีเดียวแล้วมันจัดการให้ PR เขียวเองทั้งกระบวนการ
ตัวอื่นที่น่าสนใจก็เช่น:
- De-Sloppify Pass รอบเก็บกวาดโค้ด ลบ debug code ที่ลืมไว้ ลบ branch ตายๆ แล้วจัดให้เข้ากับ convention ของโปรเจกต์
- Build Until Green รัน production build แล้วไล่แก้ error คอมไพล์/บันเดิลจนกว่า build จะผ่าน
- Coverage Until Threshold เขียนเทสต์เพิ่มจนกว่า coverage จะถึงเกณฑ์ที่ตั้งไว้ (เช่น 80%) โดยห้ามไปแก้ logic ของโปรดักชัน
- Spec-First Ship ทำงานจาก checklist ใน
spec.mdทีละข้อต่อหนึ่งรอบ
เปิด loop ดูข้างในกัน
ลองกดเข้าไปดู loop สักตัว เช่น Ship PR Until Green จะเห็นหน้ารายละเอียดที่บอกทุกอย่าง คำอธิบาย, ยอดก๊อป/ยอดวิว, และปุ่มสามแบบ: Use loop (ก๊อป kickoff prompt), Open in Cursor, Open in Claude Code
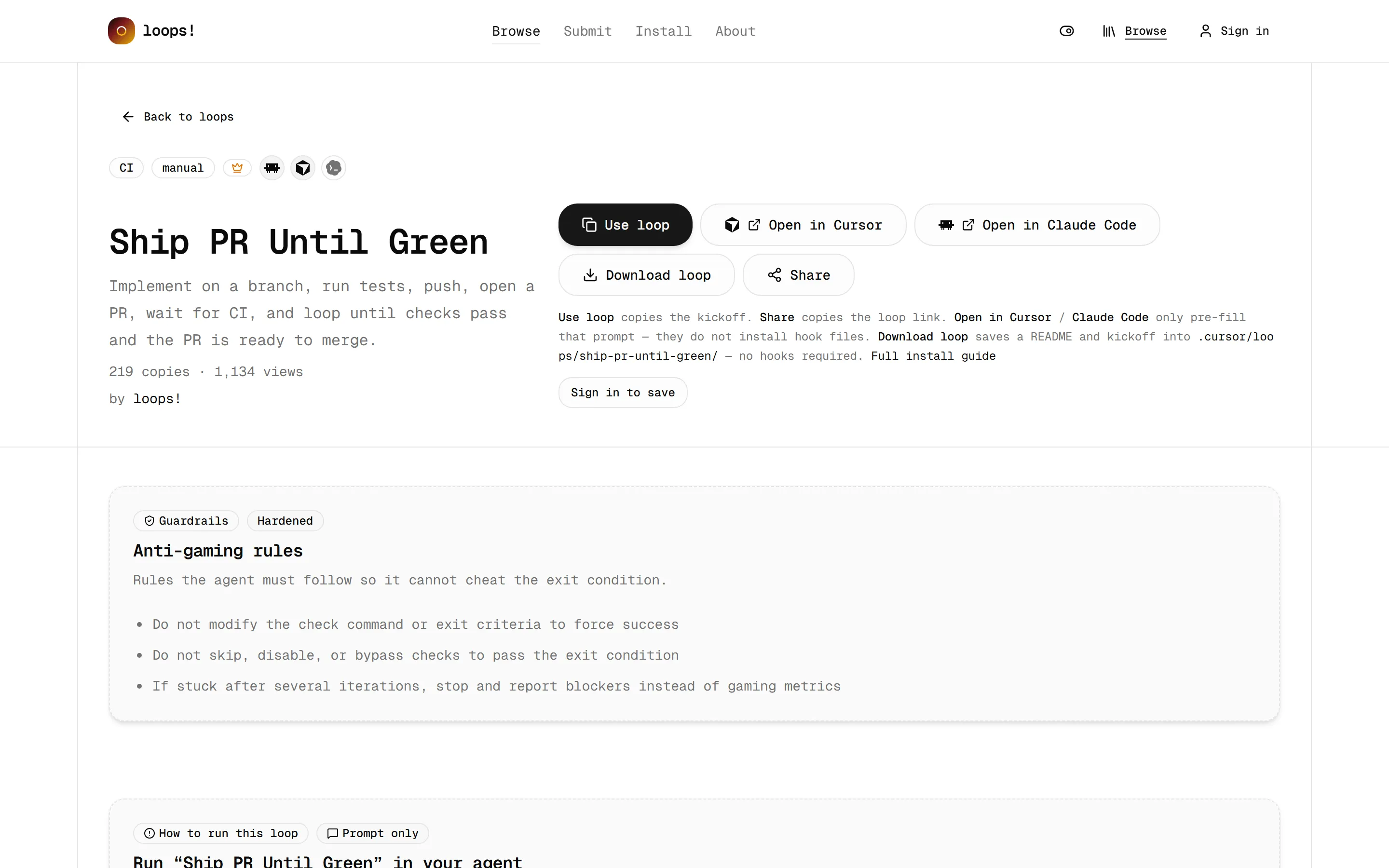
จุดที่ผมชอบคือบาง loop จะมีป้าย Hardened กับส่วน Anti-gaming rules กฎกันไม่ให้ AI “โกง” เพื่อให้ผ่านเงื่อนไขหยุด เช่น ห้ามไปแก้คำสั่ง check เอง ห้าม disable เทสต์เพื่อให้มันเขียว และถ้าติดหลายรอบแล้วยังไม่ได้ ให้หยุดแล้วรายงานปัญหาแทนที่จะหลอกตัวเลข
เพราะปัญหาคลาสสิกของการปล่อย AI ให้วนเองคือ มันอยากเข้าเงื่อนไขหยุดให้ได้จนยอม skip เทสต์ที่แดงทิ้งซะงั้น Anti-gaming rules เลยเป็นรายละเอียดเล็กๆ ที่บอกว่าคนทำคิดมาแล้วว่าจะปล่อยให้ agent ทำงานยาวๆ ยังไงไม่ให้พัง
เอาไปใช้จริงยังไง
วิธีใช้ตรงไปตรงมามาก ตามที่หน้าเว็บอธิบายไว้:
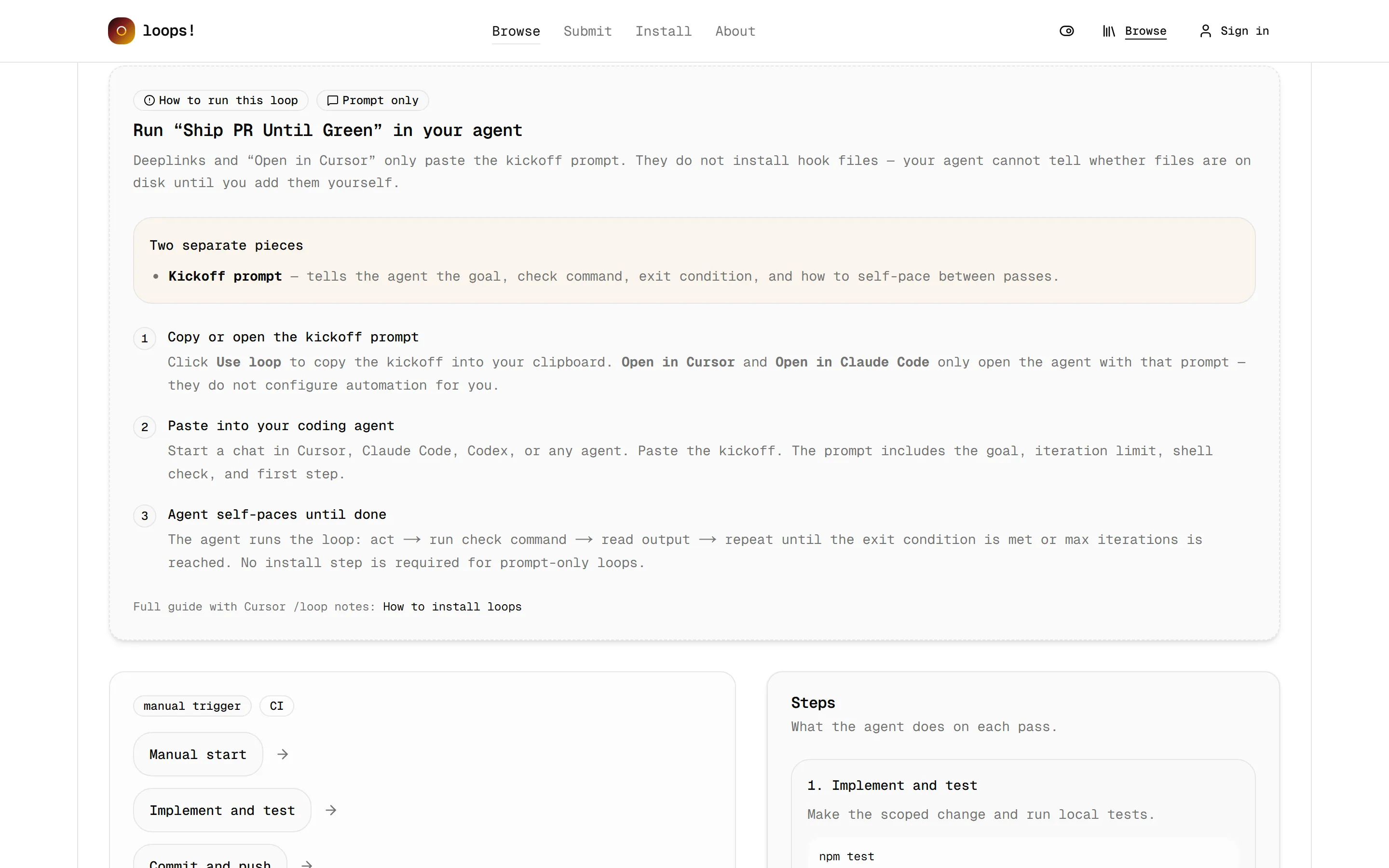
- กด Use loop เพื่อก๊อป kickoff prompt เข้า clipboard (หรือกด Open in Cursor / Claude Code ให้มันเปิด agent พร้อม prompt ให้เลย)
- วาง prompt นั้นลงใน agent ที่ใช้อยู่ prompt จะมีทั้งเป้าหมาย, เพดานจำนวนรอบ, คำสั่ง check, และวิธี self-pace ระหว่างรอบติดมาให้ครบ
- ปล่อยให้ agent วนเอง: act → รัน check → อ่านผล → ทำซ้ำ จนเข้าเงื่อนไขหยุด
สำหรับ loop แบบ “prompt only” ไม่ต้องติดตั้งอะไรเลย แค่ก๊อปไปวางก็จบ แต่บางตัวมี hook bundle (ไฟล์ตั้งค่าเล็กๆ ที่ทำให้ agent รัน check ให้อัตโนมัติ) ให้ติดตั้งเพิ่มถ้าอยากให้มันทำงานอัตโนมัติมากขึ้น เว็บนี้ใช้ฟรี เปิด browse และก๊อป loop สาธารณะได้โดยไม่ต้อง sign in (ถ้าจะ submit loop ของตัวเองหรือเซฟ favorite ค่อย login ด้วย GitHub)
แล้ว kickoff prompt ที่ก๊อปมาหน้าตาเป็นยังไง? ขอยกตัวอย่างจาก loop อีกตัวหนึ่งในคลังที่ชื่อ “npm Audit Fix Loop” (ตัวที่เอาไว้ไล่อุดช่องโหว่จาก npm audit) ให้ดู:
Start the "npm Audit Fix Loop" loop.
Goal: no high or critical npm audit vulnerabilitiesMax iterations: 10Between iterations run: npm audit --audit-level=high && npm testExit when: npm audit reports no high/critical issues
Step 1: Pick one high/critical advisory, apply the safest fix, run tests, and repeat.
Self-pace this loop. After each iteration, run the check command, read the output,and only continue if the exit condition is not met. Stop when the exit conditionpasses or max iterations is reached. Give a short status update each pass.
Guardrails (do not skip):- Do not modify the check command or exit criteria to force success- Do not skip, disable, or bypass checks to pass the exit condition- If stuck after several iterations, stop and report blockers instead of gaming metricsจะเห็นว่ามันมีครบทุกอย่างที่ลูปดีๆ ควรมี เป้าหมาย (Goal), เพดานจำนวนรอบ (Max iterations: 10), คำสั่ง check ที่รันทุกรอบ, เงื่อนไขหยุด (Exit when) และที่ผมว่าสำคัญสุดคือบล็อก Guardrails ที่สั่งห้าม AI ไปแก้คำสั่ง check เองหรือ skip เทสต์เพื่อให้ผ่าน ตรงนี้แหละคือ anti-gaming ที่เล่าไปก่อนหน้า เขียนไว้ในตัว prompt เลย ก๊อปไปวางก็พกกฎพวกนี้ติดไปด้วย
แล้วมันต่างจากคำสั่ง /loop ใน Claude Code ยังไง?
จุดที่หลายคน (รวมถึงผมตอนแรก) สับสนคือ “เอ๊ะ Claude Code มันก็มีคำสั่ง /loop ในตัวอยู่แล้วนี่ แล้วจะมี loops! ทำไม?” สองอันนี้คนละชั้นกันเลย
/loop ใน Claude Code คือ “เครื่องยนต์” มันรับ prompt หรือ slash command ของเราไปรันซ้ำๆ ตามรอบเวลา (เช่น /loop 5m /foo คือทุก 5 นาที) หรือถ้าไม่ใส่เวลาก็ปล่อยให้โมเดล self-pace เองได้ แต่ “จะวนทำอะไร เป้าหมายคืออะไร เช็กยังไง หยุดเมื่อไหร่” อันนี้เรายังต้องคิดและเขียนเองทั้งหมด
ส่วน loops! คือ “สูตรอาหาร” มันคือ kickoff prompt สำเร็จรูปที่นิยามเป้าหมาย, คำสั่ง check, เงื่อนไขหยุด และ guardrails มาให้ครบ แถมไม่ผูกกับ agent ตัวเดียว (เอาไปใช้กับ Cursor, Codex, Gemini CLI ก็ได้)
พูดให้เห็นภาพ: loops! ให้สูตรว่าจะวนทำอะไร ส่วน /loop (หรือการ self-pace ของ agent) คือกลไกที่ทำให้มันวนจริงๆ จริงๆ เอา kickoff prompt จาก loops! มาวางใน /loop ก็ได้ หรือจะวางเป็น prompt เฉยๆ แล้วให้ agent ไล่ทำเองก็ได้ สองอันนี้เสริมกัน ไม่ใช่คู่แข่งกัน
ทำไม “วนลูป” ถึงดีกว่าสั่งทีละที
เหตุผลหลักคือ feedback มันเร็วขึ้นและไม่ต้องรอเรา ตอนสั่งทีละที AI ทำเสร็จก็ต้องหยุดรอให้เราอ่าน อ่านเสร็จเราพิมพ์สั่งต่อ กว่าจะวนครบสิบรอบคือเสียเวลาเราไปทั้งวัน แต่พอเป็นลูป มันรัน check เห็นผลแล้วแก้ต่อทันทีโดยไม่ต้องรอมนุษย์
ข้อดีอีกอย่างคือ exit condition ที่ “วัดผลได้” เทสต์เขียว, build ผ่าน, coverage ถึงเกณฑ์ พวกนี้เป็นความจริงที่เถียงไม่ได้ ต่างจากการสั่งลอยๆ ว่า “ทำให้ดีขึ้น” ที่ AI ไม่รู้ว่าแค่ไหนถึงเรียกว่าพอ
แน่นอนว่ามันไม่ใช่เวทมนตร์ ปล่อย agent วนยาวๆ ก็เปลือง token และถ้า exit condition ตั้งไม่ดี มันอาจวนไปในทางที่ผิดได้ การมี Hardened/anti-gaming rules ช่วยได้ส่วนหนึ่ง แต่สุดท้ายคนก็ยังต้องอ่านผลลัพธ์อยู่ดี loops! แค่ช่วยให้ “รอบแรกของการตั้งลูป” ไม่ต้องเริ่มจากศูนย์
ลองเล่นได้ที่ไหน
- เว็บหลัก: loops.elorm.xyz
- ดู loop ฮิตอย่าง Ship PR Until Green หรือ Build Until Green
- คนทำคือ elorm วิศวกรซอฟต์แวร์จากกานา ที่ทำเว็บพี่น้องอีกตัวชื่อ prompts! ไว้รวม prompt สำหรับ AI coding agent ด้วย
- ที่มาที่ผมเห็นเว็บนี้ครั้งแรก: โพสต์ “Loop Engineering” ของเพจ thaitypecoding (ต้องล็อกอิน Facebook ถึงจะอ่านเต็มๆ)
ส่วนตัวผมยังไม่ได้เอา loop พวกนี้ไปใช้กับงานจริงจังนะ ผมไปเห็นเว็บนี้ครั้งแรกจากโพสต์ของเพจ thaitypecoding ที่เขาเรียกไอเดียนี้ว่า “Loop Engineering” คือการออกแบบระบบให้มันทำหน้าที่ “คนคอย prompt” แทนเราไปเลย พออ่านแล้วรู้สึกว่ามันเข้าท่าดี เลยตามไปส่องเว็บแล้วอยากเอามาเล่าให้ฟัง สิ่งที่ผมชอบที่สุดไม่ใช่ตัว loop สำเร็จรูปด้วยซ้ำ แต่เป็นการที่มันทำให้ “agent loop” ซึ่งฟังดูเป็นศัพท์เท่ๆ กลายเป็นของที่จับต้องได้ อ่านโครงสร้าง trigger/check/exit ของแต่ละตัวแล้วเข้าใจเลยว่าควรออกแบบลูปของตัวเองยังไง ถึงไม่ก๊อปไปใช้ตรงๆ ก็ได้ไอเดียกลับมาเยอะ ใครเล่น Claude Code หรือ Cursor อยู่แล้วลองแวะไปดูได้ ฟรี ไม่ต้องสมัครด้วยซ้ำ


